
検索結果の順位は偶然では決まりません。
検索エンジンはクロール、インデックス、ランキングという3段階の仕組みで、膨大なページから最適な答えを選びます。
この3つの流れを正しく理解することが、遠回りしないSEO対策の第一歩です。
本記事では初心者向けに、仕組みと実践方法をわかりやすく解説します。
検索エンジンの基本(クロール→インデックス→ランキング)

3つの流れを初心者向けに解説
検索エンジンはまずWeb上を巡回してページを見つけるクロールを行い、続いて内容を解析してデータベースに登録するインデックスを行います。
その上で、検索クエリごとに最適な順番で表示するランキングを計算します。
クロール→インデックス→ランキングは必ずこの順番で進み、どれか1つでも欠けると検索に表示されません。
全体像を生活の例にたとえる
クロールは「本屋で本を見つけて手に取る」段階、インデックスは「目次を作り本棚にしまう」段階、ランキングは「質問に合わせて最適な本を取り出し順に並べる」段階に相当します。
つまり、見つからない本は並べられず、目次がない本は探しにくいという仕組みです。
各工程の役割の違い
クロールは発見、インデックスは理解、ランキングは評価という役割分担です。
SEO施策はどの工程に効くのかを意識して取り組むと、ボトルネックの特定が容易になります。
例えば内部リンクは発見の支援、タイトル最適化は評価の向上に寄与します。
よくある勘違い(順位はすぐに反映されない)
公開や修正をしても、すぐに順位が上がるとは限りません。
変更がランキングに反映されるまでには、再クロールと再インデックスの時間、そして品質評価の再計算が必要です。
反映に時間がかかる主な理由
クロール頻度はサイトやURLごとに異なり、負荷や重要度に応じて調整されます。
そのため新規ページや更新が即日評価されるとは限りません。
特に新規ドメインや更新頻度が低いサイトでは、反映までに日〜数週間かかることがあります。
加えて、アルゴリズム側の再評価は段階的に進むことが多いです。
反映を待つ間にできること
内部リンクの追加、サイトマップの更新送信、重複の解消など、クロールとインデックスの促進に取り組めます。
順位はコントロールできませんが、発見と理解を助ける施策は今日から実行できます。
クロールとは?(検索ロボットがページを見つける仕組み)
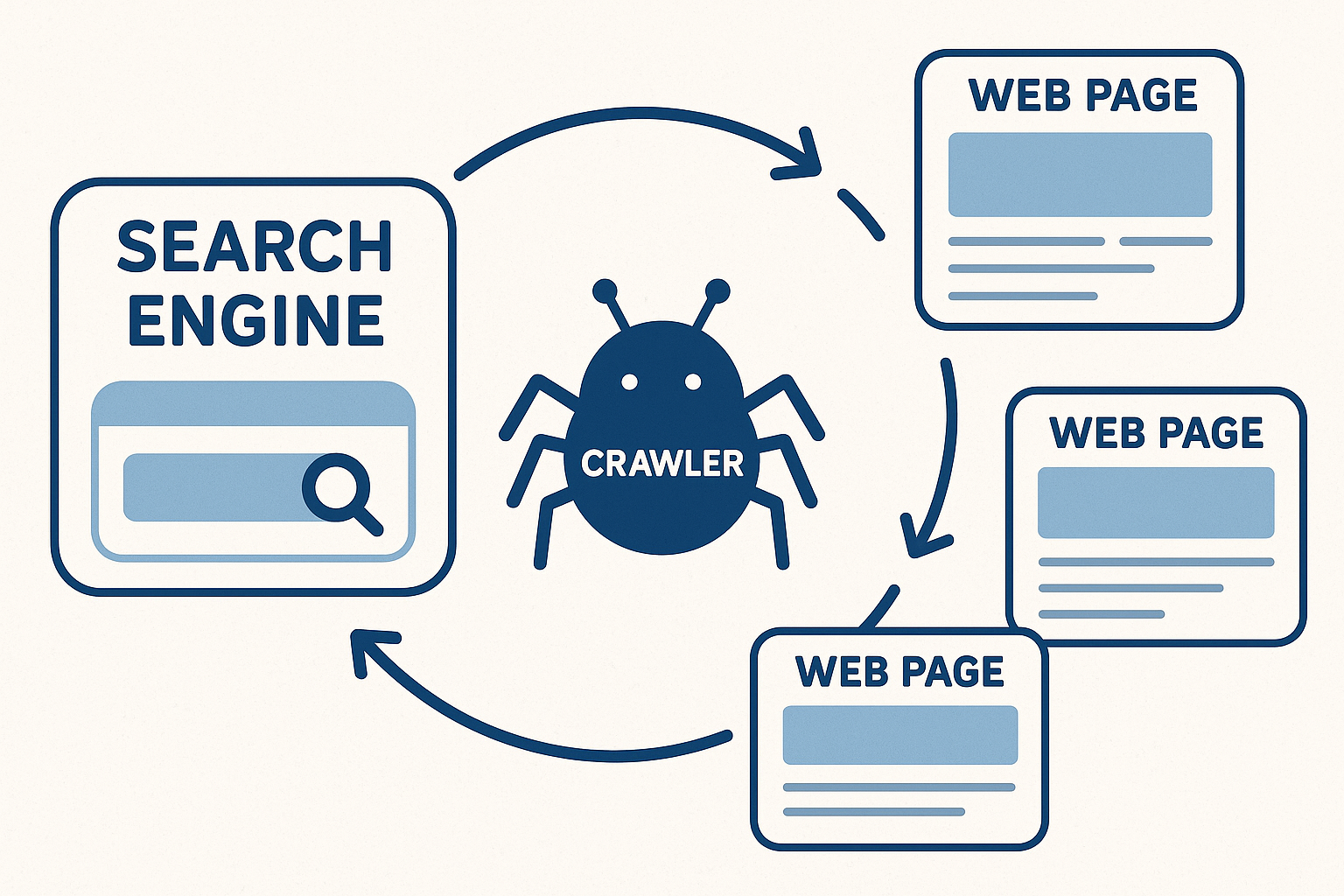
クローラー(Googlebot)の役割
Googlebotはリンクやサイトマップを手がかりにWebを巡回し、新しいページや更新を発見します。
クロールの目的は「見つけること」であり、この段階ではまだ順位は決まりません。
モバイルファーストインデックス環境では、スマートフォン用Googlebotによる取得が基準になります。
どうやってページを見つけるか
外部サイトからのリンク、内部リンク、XMLサイトマップ、過去のクロール履歴、URLパラメータの推測などが入口です。
リンクが孤立しているページは見つけにくいため、論理的なサイト構造が重要です。
クロール頻度とクロールバジェット
クロール頻度はサイトの重要度、更新頻度、サーバーの応答速度などで調整されます。
サーバーが遅い、エラーが多いとクロールが抑制され、発見の速度が落ちることがあります。
安定した配信と高速化はクロール効率の土台です。
クロールを促進する方法(サイトマップ・内部リンク)
クロールは待つだけでなく、手がかりを整えることで促進できます。
サイトマップと内部リンクの最適化は、初心者でも効果を実感しやすい基本施策です。
XMLサイトマップを整備する
サイトマップは重要URLの一覧です。
全URLを無差別に載せるのではなく、インデックスさせたい正規URLだけを掲載するのが鉄則です。
代表的な設定は次の通りです。
sitemap.xmlをルートに置き、robots.txtにSitemap: https://example.com/sitemap.xmlを記載し、Google Search Consoleで送信します。
更新のたびに自動生成される仕組みにすると運用が楽になります。
内部リンクを最適化する
関連コンテンツ同士を論理的に結び、パンくずリストやカテゴリページで階層を明確にします。
アンカーテキストはページの主題が伝わる自然な文言を使い、同一テーマのハブページを用意するとクロールと評価の両面で有利です。
クロールを阻害する設定(robots.txt・noindex)
設定を誤ると、ページが見つからなかったり、評価されない原因になります。
特にrobots.txtとnoindexの違いは必ず理解してください。
robots.txtの基本
robots.txtは「クロール可否」を指示します。
たとえばUser-agent: * / Disallow: /private/のように指定します。
これは「見に行かないで」という指示であり、インデックス除外の指示ではありません。
ブロックされたURLでも、他サイトからのリンクにより内容が不明なままインデックスされる場合があります。
noindexの使いどころ
noindexは検索結果に載せない指示です。
HTMLでは<meta name="robots" content="noindex,follow">、HTTPヘッダではX-Robots-Tag: noindexを用います。
確実に非表示にしたい場合は、noindexを使い、クロール自体は許可して指示を読ませます。
よくある阻害要因
ログイン必須ページ、エラーページの多発、遅いサーバー、無限に生成されるURLパラメータなどはクロールを浪費します。
不要なURLはrel="canonical"やURLパラメータ設定で正規化し、エラー率を下げることが重要です。
以下は混同しやすい設定の比較です。
| 設定 | 何を制御するか | 検索結果への影響 | 主な用途 |
|---|---|---|---|
| robots.txt(Disallow) | クロール | 原則インデックス制御は不可 | 管理画面や無限URLのクロール抑制 |
| meta robots noindex | インデックス | 非表示にする | 重複や薄いページの除外 |
| nofollow | リンク評価の伝播 | ランキングシグナルの伝達を抑制 | ユーザー生成リンクなどの抑制 |
| rel=canonical | 正規URLの指定 | 重複統合・評価集中 | パラメータ違いの正規化 |
除外したいときはnoindex、見に来させたくないときはrobots.txt、と役割を分けて使います。
インデックスとは?(検索データベースに登録されること)
インデックス登録の基本
クロール済みのページは、内容解析、言語判定、モバイル対応、重複処理などを経てインデックスに登録されます。
クロールされたからといって必ず登録されるわけではなく、品質や重複の観点から除外されることがあります。
正規化と重複処理
同一または類似の内容が複数URLにある場合、システムは代表URLを選びます。
意図したURLを評価させるにはrel="canonical"、内部リンクの統一、重複テンプレートの削減が有効です。
登録されにくいページ(重複・薄い内容)
価値が低い、または独自性が乏しいページは登録されにくくなります。
検索ユーザーの課題解決に寄与しないページは、たとえクロールされてもインデックス保留や未登録になる傾向があります。
具体例
・タグ一覧だけで本文がないページ ・商品バリエーションだけ違うページが乱立しているケース ・他サイトの転載が中心のページ ・サイト内検索結果ページやファセットで量産されたURL これらは統合、noindex、テンプレートの見直しで整理するのが効果的です。
回避策
独自の解説、事例、FAQ、比較表、図解などで価値を厚くします。
同じテーマでも「自分ならでは」の情報を1つでも加えると、インデックスとランキングの両方で評価されやすくなります。
インデックスの確認方法(Google Search Console)
Search Consoleはインデックス状況の把握に必須です。
「URL検査」で単一URL、「インデックス済みのページ」レポートで全体傾向を確認します。
URL検査ツールの使い方
対象URLを入力し、インデックス状態、カノニカル、モバイル取得の可否、最後のクロール日時を確認します。
インデックス未登録なら「インデックス登録をリクエスト」で再クロールを依頼できます。
ただし大量リクエストは効果的ではないため、まず技術的な問題を解決します。
カバレッジやインデックスレポートの読み方
「ページがインデックスに登録されましたが、サイトマップに送信されていません」などのメッセージは整合性のヒントです。
除外理由の内訳を見て、重複、検出-未登録、クロール済み-未登録の比率から改善優先度を決めます。
追加確認の小ワザ
Google検索でsite:example.com/対象パスと検索すると、簡易的にインデックスの有無を把握できます。
ただし精度は限定的なため、最終判断はSearch Consoleで行ってください。
ランキングとは?(どの順に表示するかを決める仕組み)
ランキングの基本軸(関連性・品質・利便性)
ランキングは大きく関連性、品質、利便性の3軸で評価されます。
この3軸のバランスを高めることが、長期的に安定した順位の近道です。
下表は各軸の代表的な観点と、初心者が最初に取り組みやすい着眼点です。
| 軸 | 代表的な観点 | 初心者の着手ポイント |
|---|---|---|
| 関連性 | クエリ一致、トピック網羅性、適切な見出し構造 | タイトルとH1の整合、主要キーワードの過不足チェック |
| 品質 | 独自性、信頼性、専門性、引用の適切さ | 出典明記、著者情報、オリジナル図表や事例の追加 |
| 利便性 | ページ速度、モバイル適合、操作性、視認性 | 画像最適化、Core Web Vitalsの改善、読みやすい段落 |
まずは意図とタイトルの整合、モバイルでの読みやすさの改善だけでも体感できる効果があります。
初心者ができる基本対策(検索意図・タイトル最適化)
最短距離の改善は、ユーザーの検索意図とページの主題を揃えることです。
検索意図を満たすタイトルと導入で、ユーザーとアルゴリズム双方に「このページは答えだ」と示します。
検索意図の読み取り方
実際の上位ページの構成、用語、網羅範囲を観察します。
「比較したいのか」「手順を知りたいのか」「定義を知りたいのか」を分類し、ページ構成を一致させます。
ずらし過ぎる独自性は離脱の原因になるため、まずは期待に応え、その上で独自要素を加えます。
タイトルタグの最適化
タイトルは約全角28〜32文字目安で要点を先頭に置き、ブランド名は末尾に短く入れます。
主キーワードは自然に1回、必要なら補助語を加え、クリックを煽り過ぎない誠実な表現にします。
例: 検索エンジンの仕組みを解説|クロール・インデックス・ランキングの基本。
メタディスクリプションと導入文
検索意図に対する結論や価値を簡潔に提示します。
ユーザーが読む理由を冒頭2〜3行で示すと、クリック後の満足度と滞在が伸びやすくなります。
コンテンツ構造と見出し
H2(H3)で論点を分け、段落では1テーマ1メッセージを意識します。
見出しに検索語の言い換えを適度に含めると、関連性が伝わりやすくなります。
アルゴリズム更新と順位の変動
Googleは定期的にコアアップデートなどの変更を実施します。
アップデートはサイトの「品質評価の再採点」に近く、一時的な振れは珍しくありません。
コアアップデートとは
品質に関する広範な調整で、特定サイトを狙い撃ちするものではありません。
長期的にはユーザー第一のサイトが評価されるよう、複数のシグナルが総合的に見直されます。
変動時の対処
短期の微調整で元に戻そうと焦らず、検索意図との整合、独自性、信頼性の改善に注力します。
変動はコントロール不能ですが、品質改善は常にコントロール可能です。
技術的問題が疑われる場合は、インデックス状況やエラーを先に確認します。
ミスリードへの注意
被リンク購入や隠しテキストなどの近道は長期的に不利で、場合によってはペナルティの対象です。
「ユーザーに価値があるか」を基準に判断すれば、アップデートのたびに右往左往せずに済みます。
まとめ
本記事では、クロール、インデックス、ランキングという3段階の仕組みと実践ポイントを解説しました。
クロールでは発見を助ける(サイトマップ・内部リンク)、インデックスでは重複と薄い内容を避ける、ランキングでは検索意図と利便性を高める、という役割別の対策が重要です。
順位は即時に変わらないことを前提に、Search Consoleで状況を把握しながら、ユーザーにとっての価値を一つずつ積み上げていきましょう。
正しい理解と地道な改善が、もっとも確実なSEOの近道です。